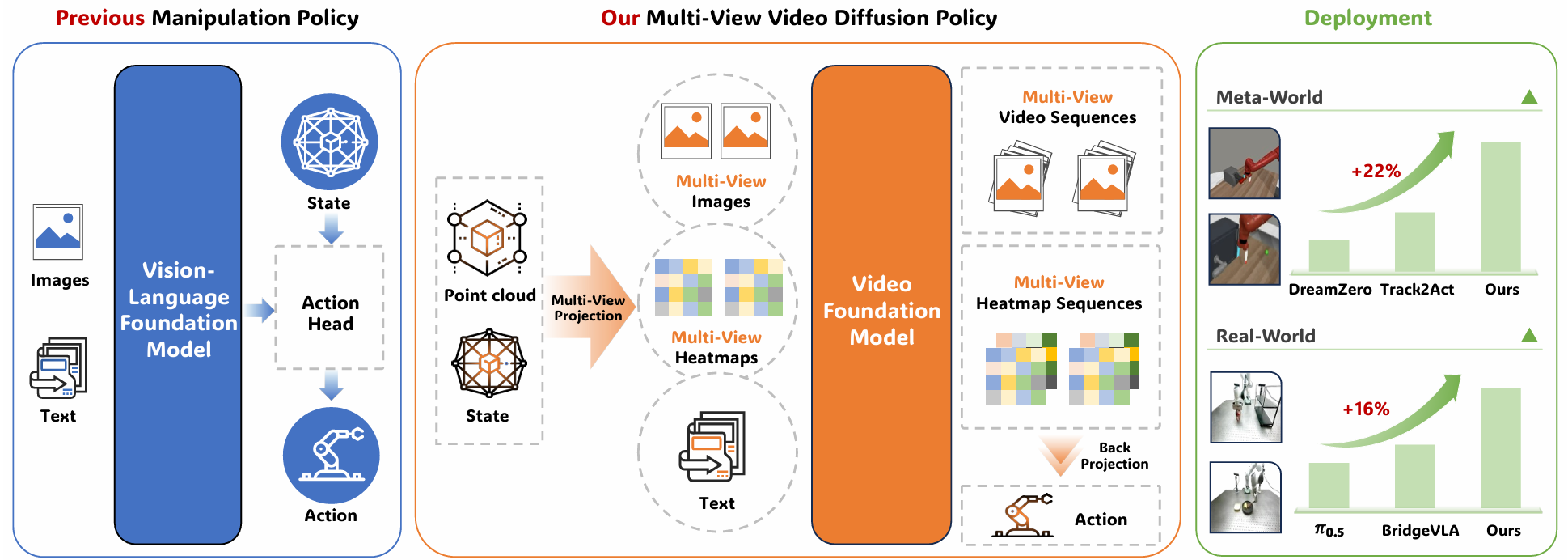
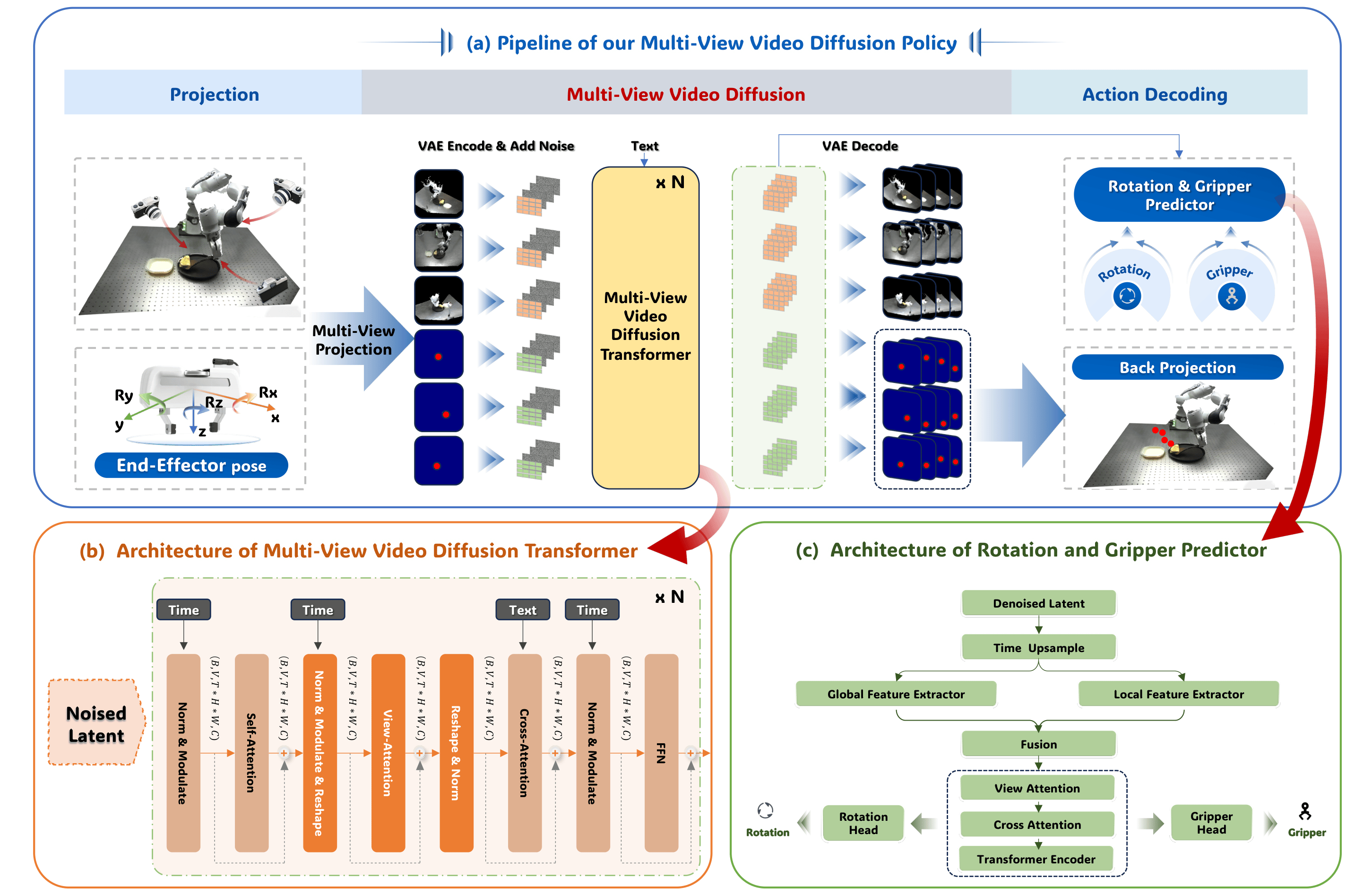
Meta-World Simulation
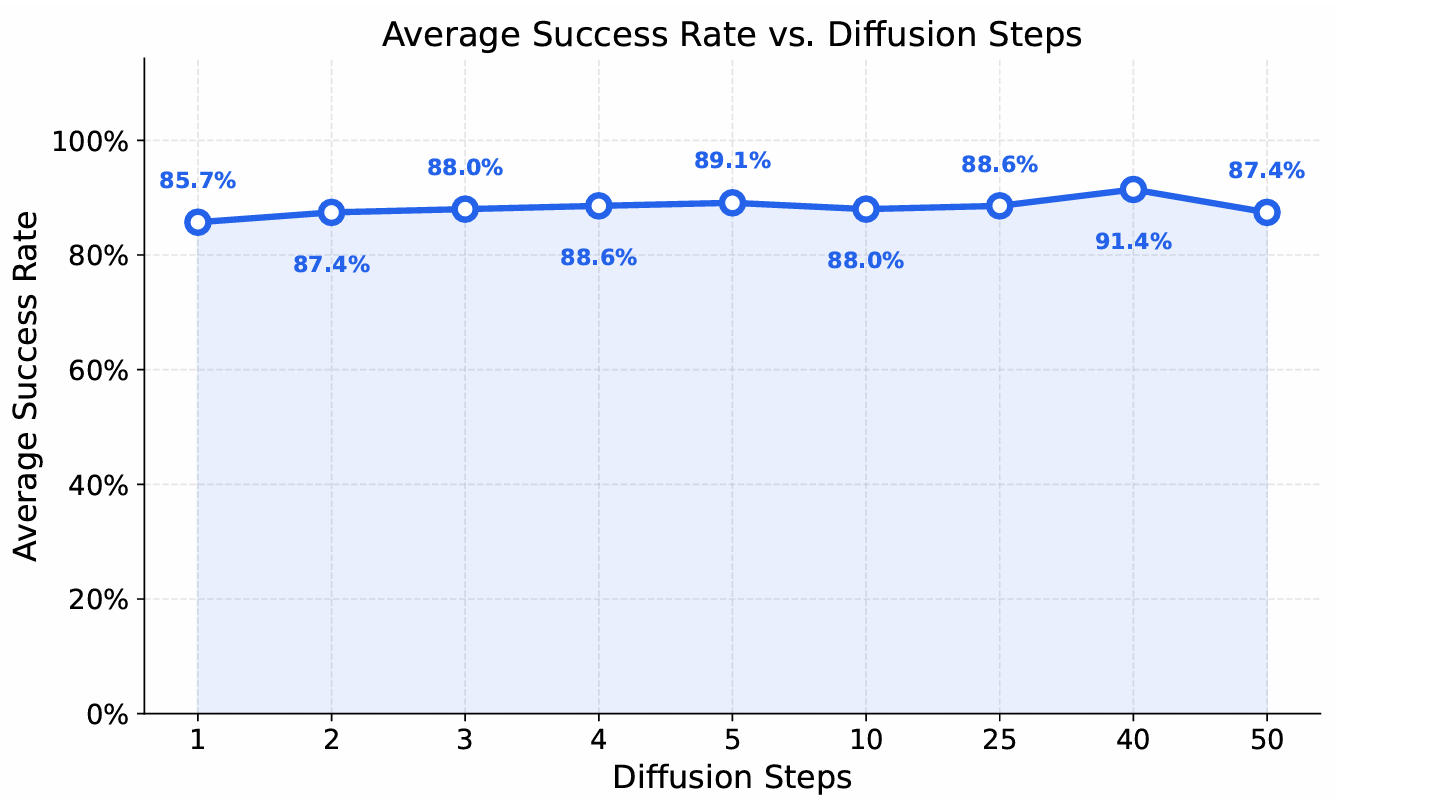
The simulation experiments focus on seven distinct Meta-World tasks, including Door-Open, Button-Press, and Faucet-Close, using only five demonstration trajectories per task to evaluate learning efficiency. MV-VDP achieves a state-of-the-art average success rate of 89.1%, significantly outperforming the next best video-prediction baseline, Track2Act (67.4%), and standard behavioral cloning methods which struggle under such limited data. These results demonstrate that aligning action fine-tuning with video foundation model pretraining effectively reduces the gap between perception and control.
| Method | Meta-World Tasks | Avg. Succ. (%) ↑ |
||||||
|---|---|---|---|---|---|---|---|---|
| D-Open | D-Close | Btn | Btn-Top | Fct-Cls | Fct-Open | Handle | ||
| UniPi(Du et al., 2023) | 0/25 | 9/25 | 3/25 | 0/25 | 1/25 | 3/25 | 4/25 | 11.40 |
| BC-Scratch(Nair et al., 2022) | 6/25 | 9/25 | 9/25 | 3/25 | 5/25 | 5/25 | 9/25 | 26.20 |
| BC-R3M(Nair et al., 2022) | 1/25 | 15/25 | 9/25 | 1/25 | 6/25 | 17/25 | 13/25 | 35.40 |
| DP(Chi et al., 2025) | 12/25 | 12/25 | 10/25 | 5/25 | 6/25 | 15/25 | 6/25 | 37.70 |
| AVDC(Ko et al., 2023) | 18/25 | 23/25 | 15/25 | 6/25 | 14/25 | 6/25 | 21/25 | 58.90 |
| DreamZero(Ye et al., 2026) | 0/25 | 11/25 | 23/25 | 3/25 | 20/25 | 25/25 | 25/25 | 61.10 |
| Track2Act(Bharadhwaj et al., 2024b) | 22/25 | 19/25 | 14/25 | 10/25 | 12/25 | 22/25 | 19/25 | 67.40 |
| MV-VDP (Ours) | 25/25 | 25/25 | 25/25 | 24/25 | 8/25 | 24/25 | 25/25 | 89.10 |
Table 1: Success rates on seven Meta-World tasks under a low-data regime (5 demonstrations per task). Each entry reports the number of successful rollouts out of 25 trials. Our method (MV-VDP) achieves the highest average success rate and consistently outperforms prior video-prediction and behavior-cloning baselines.
Button Press
Episode 1
Episode 2
Episode 3
Button Press Topdown
Episode 1
Episode 2
Episode 3
Door Close
Episode 1
Episode 2
Episode 3
Door Open
Episode 1
Episode 2
Episode 3
Faucet Close
Episode 1
Episode 2
Episode 3
Faucet Open
Episode 1
Episode 2
Episode 3
Handle Press
Episode 1
Episode 2
Episode 3
Real-World Base Tasks
The real-world evaluation involves a Franka Research 3 robot performing three foundational tasks: Put Lion (pick-and-place), Push-T (complex pushing), and Scoop Tortilla (contact-rich manipulation). With fewer than ten expert demonstrations, MV-VDP reaches a 100% success rate on the Put Lion task and successfully manages the continuous dynamics of pushing and scooping where prior key-pose-based methods like BridgeVLA often fail. By predicting continuous action chunks rather than isolated waypoints, the model maintains the precise temporal coordination required for high-dexterity tasks.
| Method | Basic Tasks | Unseen Tasks | Avg. Succ. (%) ↑ |
|||||
|---|---|---|---|---|---|---|---|---|
| Put Lion | Push-T | Scoop Tort. | Put-B | Put-H | Push-L | Scoop-C | ||
| DP3(Ze et al., 2024) | 0/10 | 0/10 | 0/10 | 0/10 | 0/10 | 0/10 | 0/10 | 0.00 |
| π0.5(Black et al., 2025a) | 1/10 | 0/10 | 0/10 | 0/10 | 0/10 | 0/10 | 0/10 | 1.40 |
| UVA(Li et al., 2025d) | 2/10 | 0/10 | 0/10 | 1/10 | 1/10 | 0/10 | 0/10 | 5.70 |
| BridgeVLA(Li et al., 2025b) | 9/10 | 0/10 | 4/10 | 8/10 | 7/10 | 0/10 | 1/10 | 41.42 |
| MV-VDP (Ours) | 10/10 | 4/10 | 7/10 | 5/10 | 6/10 | 3/10 | 5/10 | 57.10 |
Table 2: Real-world manipulation results under limited demonstrations. We report success rates over 10 trials per task on three basic tasks and four unseen tasks. All methods are trained with 10 expert trajectories.
Scoop the tortilla into the plastic plate
Trial 1
Trial 2
Trial 3
Push the T Block into the target region
Trial 1
Trial 2
Trial 3
Put the lion on the shelf
Trial 1
Trial 2
Trial 3
Generalization to Unseen Scenarios
To test robustness, the model is deployed in four "unseen" settings: novel backgrounds (Put-B), increased object height (Put-H), dark lighting (Push-L), and an entirely new object category (Scoop-C, using plastic noodles). MV-VDP demonstrates strong generalization, particularly in lighting and category variations, achieving an average success rate of 57.1% across all real-world tasks compared to just 41.4% for the strongest Vision-Language-Action baseline. This suggests that the 3D-aware multi-view projections provide a more resilient representation of the environment than standard 2D or MLP-based 3D encoders.
Background Variation
Trial 1
Trial 2
Category Variation
Trial 1
Trial 2
Height Variation
Trial 1
Trial 2
Lighting Variation
Trial 1
Trial 2
Video Generation Showcase
Meta-World
button-press
door-open
faucet-close
Real-World
Scoop the tortilla into the plastic plate
Push the T Block into the target region
Put the lion on the shelf